



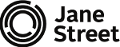

Omówienie zadania Prognoza pogody (II etap XXXIII OI)
Rozwiązanie \(O(m^2n)\) - podzadanie \(n\leq 1000\)
Aby otrzymać takie rozwiązanie, możemy obliczyć minimum z zadania wprost z definicji. Dla każdego przesunięcia cyklicznego prognozy Bajtka (których jest \(m\)) oraz każdej pozycji w ciągu faktycznych temperatur, do której można przyłożyć prognozę (których jest \(n-m+1\)), porównujemy wszystkie \(m\) elementów prognozy z odpowiadającymi im elementami w ciągu faktycznych temperatur i zliczamy, ile z nich się nie zgadza. Ostatecznie wynikiem jest minimum z tych wartości.
Takie rozwiązanie wykona dokładnie \(m^2\cdot (n-m+1)\) porównań elementów, co daje nam złożoność czasową \(O(m^2n)\).
Rozwiązanie dla temperatur z zakresu od 0 do 1
Załóżmy, że nasze temperatury są liczbami całkowitymi z zakresu od 0 do 1. Wówczas zarówno ciąg temperatur jak i potencjalną prognozę możemy traktować jako ciągi binarne. Wykorzystując odpowiednie instrukcje procesora, możemy porównywać takie ciągi znacznie wydajniej niż dowolne ciągi.
Załóżmy, że rozmiar rejestru procesora to \(w\) bitów. Na współczesnych komputerach \(w\) jest zazwyczaj równe 64. Mając dwa ciągi binarne \(a\) oraz \(b\) długości \(w\) reprezentowane jako liczby całkowite w rejestrach procesora, możemy znaleźć liczbę pozycji, na których te ciągi się różnią, za pomocą stałej liczby instrukcji procesora. Aby to zrobić, możemy najpierw obliczyć bitowy XOR tych dwóch liczb. Wiemy, że w wyniku tej operacji otrzymamy liczbę, której bity ustawione na 1 odpowiadają pozycjom, na których ciągi \(a\) oraz \(b\) się różnią. Następnie możemy skorzystać z instrukcji procesora, która zlicza liczbę bitów ustawionych na 1 w danej liczbie całkowitej (np. \(\texttt{__builtin_popcount}\) lub \(\texttt{__builtin_popcountll}\) w języku C++, korzystając z kompilatora GCC). W ten sposób jesteśmy w stanie porównać \(w\) elementów naszych ciągów na raz.
Możemy więc reprezentować prognozę jako ciąg \(\lceil m/w \rceil\) liczb całkowitych, a ciąg faktycznych temperatur jako ciąg \(\lceil n/w \rceil\) liczb całkowitych, gdzie każda liczba całkowita reprezentuje \(w\) kolejnych elementów prognozy lub ciągu temperatur (poza ostatnimi, które mogą reprezentować mniej niż \(w\) elementów). Następnie, wybierając odpowiednio indeksy i korzystając z odpowiednich operacji bitowych, możemy obliczyć liczbę niezgodności między prognozą a ciągiem faktycznych temperatur przy przyłożeniu tej prognozy do pewnej pozycji w tym ciągu w złożoności \(O(m/w)\). Szczegóły tych operacji pozostawiamy jako ćwiczenie dla Czytelnika.
Ostatecznie, wykonując powyższe dla wszystkich \(m\) przesunięć cyklicznych prognozy oraz wszystkich \(n-m+1\) pozycji, do których można przyłożyć prognozę, otrzymujemy rozwiązanie o złożoności czasowej \(O(m^2n/w)\) i pamięciowej \(O(n/w)\).
Rozwiązanie dla nierosnącego ciągu temperatur
Podzielmy ciąg faktycznych temperatur na fragmenty w taki sposób, że w obrębie każdego z tych fragmentów temperatury są takie same, a między dwoma sąsiednimi fragmentami temperatura się zmienia. Skoro wiemy, że ciąg ten jest nierosnący, a temperatury są liczbami całkowitymi z zakresu od -20 do 40 (włącznie), to liczba takich fragmentów wyniesie co najwyżej 61.
Powiedzmy, że chcemy przyłożyć pewną prognozę \(p_0, p_1, \ldots, p_{m-1}\) do pozycji \(i\) w ciągu faktycznych temperatur. Możemy wówczas spojrzeć na fragmenty ciągu temperatur, na których temperatury są stałe, od pozycji \(i\) do pozycji \(i+m-1\) (czyli na fragmenty, które pokrywają się z prognozą przyłożoną do pozycji \(i\)). Jeśli mamy pewien fragment zaczynający się na pozycji \(i+k\) i kończący się na pozycji \(i+l\) (gdzie \(0\leq k\leq l\leq m-1\)), a faktyczna temperatura w tym fragmencie jest równa \(t\), to do liczby niezgodności musimy dodać liczbę elementów pośród \(p_k, p_{k+1}, \ldots, p_l\), które są różne od \(t\). Tę liczbę możemy poznać w czasie stałym, jeśli wcześniej dla każdego \(j=0,1,\dots,m-1\) oraz każdej temperatury \(t\) obliczymy liczbę elementów pośród \(p_0, p_1, \ldots, p_j\), które są różne od \(t\) i skorzystamy ze znanego pomysłu sum prefiksowych.
W ten sposób możemy obliczyć liczbę niezgodności między prognozą a ciągiem faktycznych temperatur przy przyłożeniu tej prognozy do pozycji \(i\) w czasie \(O(D)\), gdzie \(D=61\) to maksymalna liczba fragmentów w ciągu temperatur. Dla ustalonej prognozy pogody możemy potwórzyć to dla wszystkich \(i\) od \(0\) do \(n-m\) w czasie \(O(nD)\) przy wykonaniu wstępnych obliczeń w złożoności \(O(mD)\).
Powyższy algorytm można potwórzyć dla wszystkich \(m\) przesunięć cyklicznych, co daje ostateczną złożoność czasową \(O(mnD)\) i pamięciową \(O(mD+n)\).
Rozwiązanie \(O(mn)\) - wzorcowe
Przyłóżmy prognozę do ciągu faktycznych temperatur rozpoczynając od pozycji \(i\) w tym ciągu. Następnie przesuńmy naszą prognozę cyklicznie o jedną pozycję w lewo (pierwszy element trafia na koniec, pozostałe przemieszają się na indeks o jeden mniejszy). Tak przesuniętą prognozę przyłóżmy do pozycji \(i+1\) w ciągu faktycznych temperatur (patrz przykład poniżej).
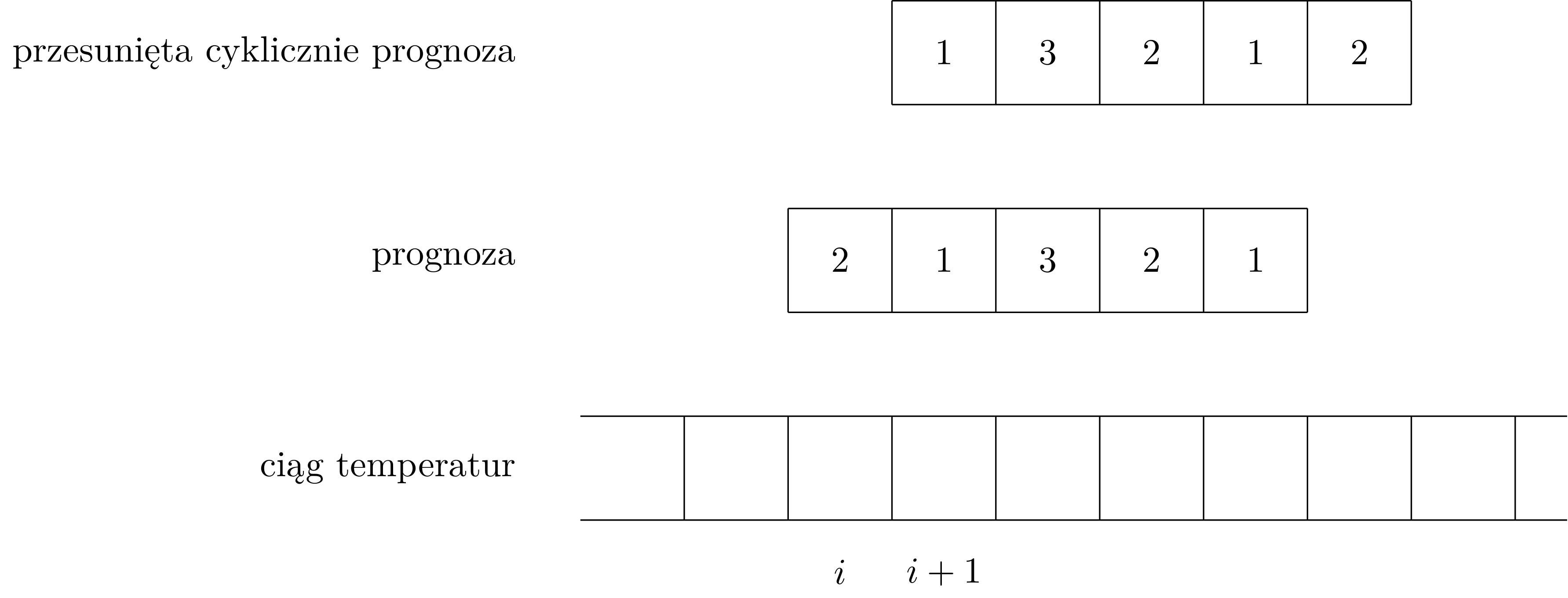
Widzimy, że przy obu przyłożeniach na pozycjach od \(i+1\) do \(i+m-1\) (gdzie \(m\) to długość prognozy) porównujemy dokładnie te same elementy prognozy z tymi samymi elementami ciągu faktycznych temperatur. Jedyna różnica jest taka, że w pierwszym przyłożeniu pierwszy element prognozy porównujemy z elementem na pozycji \(i\) w ciągu faktycznych temperatur, a w drugim przyłożeniu ostatni element przesuniętej cyklicznie o jedną pozycję w lewo prognozy porównujemy z elementem na pozycji \(i+m\) w ciągu faktycznych temperatur.
Ta obserwacja oznacza, że jeśli znamy liczbę niezgodności między prognozą a ciągiem faktycznych temperatur przy przyłożeniu tej prognozy do pozycji \(i\), to możemy w czasie stałym obliczyć liczbę niezgodności przy przyłożeniu prognozy przesuniętej cyklicznie o jedną pozycję w lewo do pozycji \(i+1\) w tym ciągu.
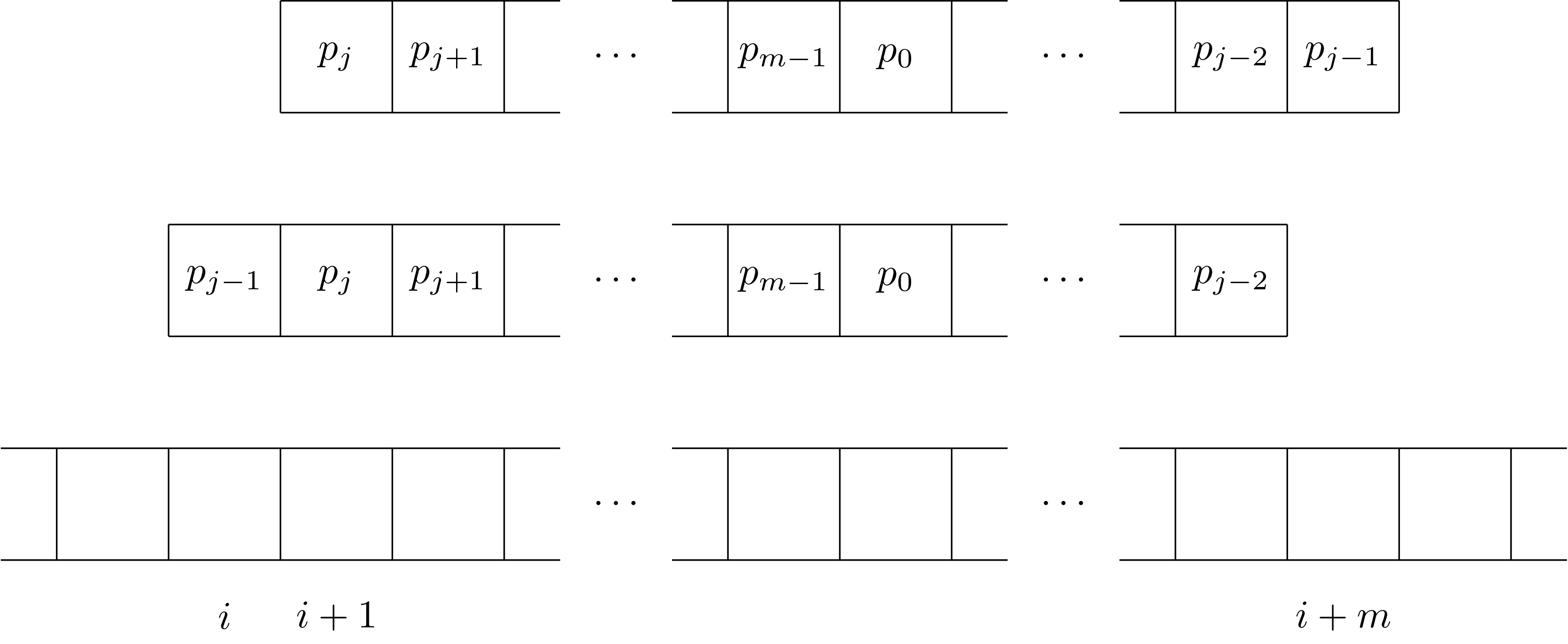
Przyjmijmy, że prognoza pogody z wejścia to \(p_0, p_1, \ldots, p_{m-1}\), a ciąg temperatur to \(t_0, t_1, \ldots, t_{n-1}\). Dla \(i=0, 1, \ldots, n-m\) oraz \(j=0, 1, \ldots, m-1\) niech \(d(i,j)\) oznacza liczbę niezgodności między prognozą przesuniętą cyklicznie o \(j\) pozycji w lewo (czyli \(p_j, p_{j+1}, \ldots, p_{m-1}, p_0, \ldots, p_{j-1}\)) a ciągiem faktycznych temperatur przy przyłożeniu tej prognozy do pozycji \(i\) w tym ciągu.
Wartości \(d(0,j)\) możemy obliczyć dla wszystkich \(j=0,1,\dots,m-1\) w łącznym czasie \(O(m^2)\) prosto z definicji. Załóżmy, że znamy już wartości \(d(i,j)\) dla pewnego \(i\) oraz wszystkich \(j=0,1,\dots,m-1\). Wówczas możemy obliczyć wartości \(d(i+1,j)\) dla wszystkich \(j=0,1,\dots,m-1\) w czasie \(O(m)\) korzystając z następującego wzoru: \[ d(i+1,j)=d(i,(j-1)\text{ mod }m)-[p_{(j-1)\text{ mod } m}\neq t_i]+[p_{(j-1)\text{ mod } m}\neq t_{i+m}], \] gdzie \[ [\text{zdarzenie}\, A] = \begin{cases} 1 & \text{jeśli } A \text{ jest prawdziwe},\\ 0 & \text{w przeciwnym razie}. \end{cases} \] jest tak zwanym nawiasem Iversona.
Zwróćmy uwagę, że wyrażenie \((j-1)\text{ mod } m\) oznacza po prostu indeks, który jest o jeden mniejszy niż \(j\) dla \(j>0\) oraz indeks \(m-1\) dla \(j=0\). Motywacja powyższego wzoru została dodatkowo przedstawiona na ilustracji poniżej.
Oczywiście odpowiedź w zadaniu to najmniejsza z wartości w tabelce \(d\). Pokazaliśmy więc, że możemy obliczyć wszystkie te wartości w łącznym czasie \(O(m^2+mn)=O(nm)\), jednak takie rozwiązanie ma także złożoność pamięciową rzędu \(O(mn)\), co nie pozwala zmieścić się w limicie pamięci tego zadania. Aby zredukować zużycie pamięci, możemy na przykład reprezentować wartości w tabelce \(d\) jako liczby 16-bitowe, gdyż ograniczenie na wynik w naszym zadaniu jest takie samo jak ograniczenie na \(m\), czyli 10'000, co mieści się w zakresie tego typu całkowitego. Takie rozwiązanie otrzymywało więcej punktów, jednak nie pozwalało uzyskać ich kompletu.
Aby rozwiązać zadanie w pełni, wystarczy zauważyć, że do obliczenia wartości \(d(i+1,j)\) dla wszystkich \(j\) potrzebujemy tylko wartości \(d(i,j)\) dla wszystkich \(j\). Dzięki temu w podczas obliczeń wystarczy przechowywać co najwyżej dwie "kolumny" tej tabeli w danym momencie, co pozwala zredukować złożoność pamięciową do \(O(m+n)=O(n)\).